Forward Test of MMAR ×
LLM-Emitted Regime Signal
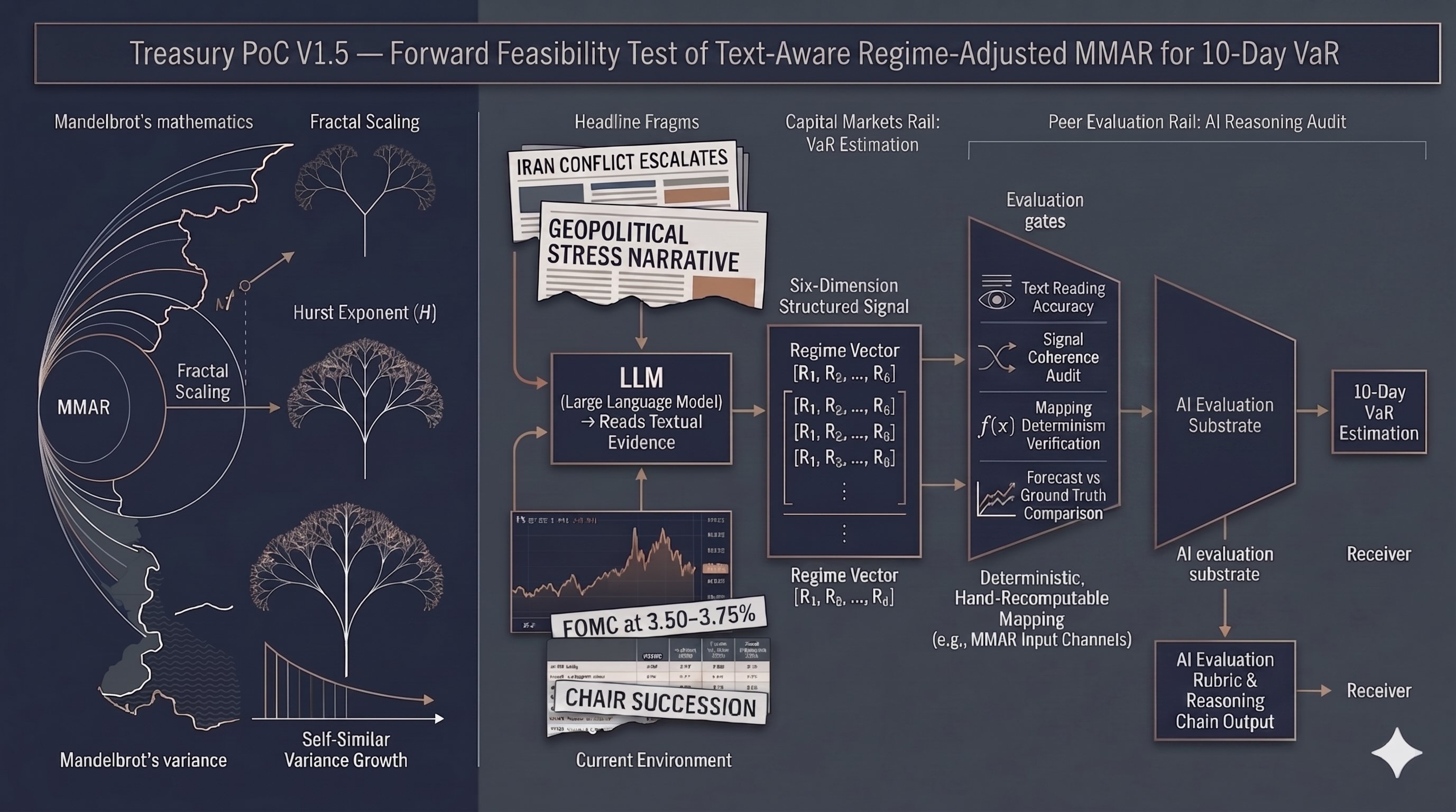
A feasibility test of an architecture, not an alpha claim.
The PoC
A $30 million synthetic UST book — $10M each in 2Y, 5Y, and 10Y — held through a 10-trading-day window opening April 28, 2026. The window contains a live FOMC meeting on its first day.
The score was frozen the morning of April 27 against a corpus closing the previous Friday. All numeric coefficients are V1 illustrative. The property under test is whether the architecture runs end-to-end — not whether the coefficients are calibrated.
The Methodology
An LLM reads textual regime evidence and emits a structured six-dimension signal. A six-anchor severity rubric tied to dated historical regimes makes the score replicable across observers. A documented conflict-resolution rule handles divergent voices.
The signal flows through a deterministic, hand-recomputable mapping into three engine inputs: a Hurst-exponent adjustment (ΔH), a volatility multiplier, and a tail multiplier. Three engines compare: Gaussian baseline, static MMAR, Nexus-adjusted MMAR.
Forward Discipline
Bar 2 forward: single LLM, single pass, no internet during scoring, frozen corpus. The score was locked before any project-window data existed, and will not be moved during the window.
The May 11 backtest will compare realized 10-day P&L against published thresholds. A single window is feasibility, not calibration. Multi-window calibration is V2 work.
Auditable channel decomposition.
The +38.5% E1→E3 lift in 10-day VaR_99 decomposes cleanly: +19.8% pure MMAR self-similarity (text-blind) and +15.7% text-aware regime channel. The deterministic-mapping arithmetic checks to two decimals. Severity-adjacency analysis shows non-monotonicity under anchor-character-consistent dimensions — a feature of the architecture, not a bug, demonstrating that dimensional structure dominates headline severity.
Bar 2 forward as an evaluation substrate.
Bar 2 forward discipline isolates the calibration question from the comprehension question. The four-question reasoning decomposition (text reading / signal coherence / deterministic mapping / forecast vs ground truth) gives an auditable evaluation substrate where each question is addressable by a different methodology. The architecture's commitment to a deterministic mapping is a counter to "LLMs are black boxes" — the audit trail is complete from the structured signal forward.
Two channels, decomposed cleanly.
Three documents, companion artifacts.
The detailed findings is the primary artifact. The executive summary is the entry point for senior readers. The methodological questions appendix names what V2 must address before institutional pilot — including the three new questions (Q11–Q13) added during pre-publication adversarial review.
Executive Summary
The 13-page condensation. Cover, three-paragraph "At a Glance," position and three-engine results, methodology defenses (five structural differences from sentiment and a summary of the EMH defense), the non-monotonicity finding, the four-question reasoning decomposition, literature and novelty, inside-window events, and the May 11 realized outcome section.
Detailed Findings
The 44-page document. Sections covering thesis, baselines, corpus and coverage, six-dimension scoring with verbatim Fed quotes, methodology defenses (APGAR/Glasgow analogy, five structural differences from sentiment, and the full Section 7B EMH defense — six responses including the Grossman-Stiglitz argument), sensitivity analyses with the non-monotonicity finding, three-engine results with channel decomposition and per-tenor breakdown, reasoning capability decomposition, forward backtest framework, V1 limitations, literature and novelty, Section 14 events inside the project window, and Section 14.4 — the May 11 realized outcome.
Methodological Appendix
Fourteen open questions and a V2 priority ranking. Q11 (independent derivation of historical anchor profiles) is priority 1 — the falsifying test for the central architectural claim. Q14 (added in this revision) is priority 3 — the EMH-redundancy falsification test, pre-registered with Expected Shortfall as primary metric, three named statistical tests, a stratified 60+ window protocol, and a quantitative falsification threshold. The appendix names the empirical tests V2 must run before any institutional pilot.
01_baselines.py, 02_engines.py, 03_charts.py, 04_make_pdfs.py. The deterministic mapping is hand-recomputable on a calculator. A public GitHub repository will accompany the V2 release alongside multi-window calibration data; for V1, code is described in the documents and available on request.
The window closes May 11.
Realized 10-day loss: $114,339. No breaches at 95% or 99%.
The $30M synthetic UST book closed the April 28 – May 11 window with a realized 10-day loss of $114,339 — 37% of the lowest published threshold (E1 VaR_95 = $307,162) and 19% of the highest (E3 VaR_99 = $601,725). All six published thresholds held. This is Outcome A — the modal expected result in a calm regime — and establishes face validity of the V1.5 publication: the architecture ran end-to-end under Bar 2 forward discipline with zero post-hoc adjustments. A single no-breach window cannot distinguish between well-calibrated, conservatively-calibrated, and uninformative — multi-window calibration is V2 work.
Section 7B engages the Efficient-Market objection at the architectural level. The empirical question — whether the LLM-emitted regime channel adds information beyond the price-derived Hurst signal — is formalized in Q14, the EMH-redundancy falsification test pre-registered for V2. Q14 commits to Expected Shortfall as primary metric, three named statistical tests (Diebold-Mariano, encompassing, likelihood-ratio), a stratified 60+ window protocol, and a quantitative falsification threshold (rejection at p < 0.05 with effect size > 5%). If Q14's null is not rejected, the framework's forecasting-edge claim is refuted and positioning revises to auditability-only. V2 publishes the falsifying outcome.